
Data lifecycle management: A complete guide to governing data from creation to deletion
Mar 10, 2025
Data lifecycle management (DLM) turns scattered retention policies, ungoverned access, and orphaned datasets into a defensible, policy-driven program. With 77% of organizations now operating hybrid environments and privacy regulations multiplying across jurisdictions, DLM provides the framework to keep sensitive data available, secure, and compliant at every stage, from creation through deletion.
Data lifecycle management sits at the center of an uncomfortable gap in most organizations' security programs. According to the Netwrix Hybrid Security Trends Report 2024, data classification is the number-one security measure organizations plan to implement, yet only about half have actually done it.
The gap between intention and execution means sensitive data accumulates without defined owners, retention policies, or appropriate access controls. Over time, that ungoverned data becomes the exact attack surface that regulators and threat actors exploit. The problem compounds in hybrid environments.
With 77% of organizations now operating across on-premises and cloud infrastructure, per the Netwrix Cybersecurity Trends Report 2025, data spreads across more systems, jurisdictions, and identity boundaries than most governance programs were designed to handle.
Data lifecycle management provides the operational discipline to close this gap: connecting classification, access governance, retention policies, and audit evidence into a program that works across the full data lifecycle.
What is data lifecycle management?
Data lifecycle management (DLM) is a policy-based approach to managing data from creation through storage, use, archival, and deletion. The goal is to keep data available, secure, and compliant at every stage, not only when an auditor requests evidence.
Four core goals drive every effective DLM program:
- Right access at the right time: The right people, and only the right people, can reach the data they need, with appropriate controls at every stage.
- Integrity and consistency: Data stays accurate, complete, and trustworthy throughout its operational life, supporting sound decisions and reliable analytics.
- Security and compliance risk mitigation: Policies reduce exposure to breaches, regulatory penalties, and the operational chaos that comes from data nobody owns or governs.
- Full lifecycle governance: Data is actively managed from the moment it enters the environment to the moment it is retired. That means defined ownership, retention schedules, and disposition workflows at every stage, so data does not accumulate past its useful life and become a liability nobody can account for.
Data lifecycle management is not the same as information lifecycle management (ILM). DLM deals with raw data assets, including files and databases, along with their attributes such as type, size, and age. ILM goes further to encompass how different pieces of raw data connect to form business information, such as a purchase order composed of records across multiple systems.
Both disciplines cover structured and unstructured content across on-premises and cloud environments, but DLM is the operational foundation that ILM builds on.
Why data lifecycle management matters
The business case for DLM touches every part of the organization. It starts with cost. As hybrid environments grow and cloud workloads expand, organizations without lifecycle policies end up paying hot-storage prices for data that nobody has accessed in years.
Archiving cold data to cheaper tiers, eliminating redundant copies, automating lifecycle transitions, and minimizing data that no longer serves a business purpose are straightforward ways to reduce infrastructure spending and shrink the attack surface, but they require policies that define when and how data moves.
Then there is regulatory pressure:
- HIPAA mandates multi-year retention for compliance documentation
- SOX requires retaining certain financial records with controls against improper alteration
- CMMC and similar frameworks impose baseline auditability requirements on organizations selling into government supply chains
These obligations overlap, and data deletion and "do not share" requests under privacy regulations add operational burden on top of retention rules. DLM provides a single operational framework to meet these requirements without building separate programs for each regulation.
Security exposure ties it all together. Ungoverned data, particularly sensitive data sitting past its retention date or accessible to overly broad user groups, expands the attack surface and increases the cost of incidents when they occur.
Every dataset without a defined owner, retention policy, or appropriate access control is a liability waiting to surface during a breach investigation or regulatory audit.
Netwrix DSPM finds and protects sensitive data across on-premises, hybrid, and cloud environments. Request a demo
Core components of a data lifecycle management program
Before examining the lifecycle stages themselves, four components form the operational backbone of an effective DLM program. These need to be in place to govern data at any stage.
Data classification and cataloging
Teams cannot govern what they cannot see. Cataloging data assets and applying consistent classification (public, internal, confidential, regulated) is the foundation everything else builds on. Classification should happen automatically at ingestion and update as data moves through lifecycle stages.
The metadata captured, including sensitivity level, regulatory requirements, business owner, retention schedule, and access patterns, drives every downstream decision about retention, access, and protection.
Policies for retention, access, and quality
Policies fall into three categories, and all three need to work together:
- Retention policies define how long each data type must be kept, when it should be archived, and when it should be deleted, aligned with applicable regulatory and contractual requirements.
- Access policies define who can reach what data, under what conditions, and with what level of approval, mapped to data classification and evolving as data moves through lifecycle stages.
- Quality policies establish standards for accuracy, completeness, and timeliness for key datasets, with clear remediation workflows when data falls below thresholds.
The challenge for organizations operating across multiple jurisdictions is harmonizing these policies across overlapping and sometimes conflicting regulatory requirements.
Storage tiering and cost optimization
Not all data deserves the same storage treatment. Map datasets to storage tiers (hot, warm, cold, archive) based on access patterns and business value.
Active data supporting daily operations belongs on high-performance storage. Archival data that only surfaces during audits or legal holds belongs on the cheapest available storage that still meets accessibility requirements.
Monitoring, auditing, and lifecycle automation
Manual lifecycle management does not scale. Automated systems need to track data movement between stages, detect policy violations, and provide audit evidence.
Monitoring should cover:
- Data access patterns
- Permission changes
- Lifecycle transitions
- Policy exceptions
Auditing needs to produce evidence mapped to specific compliance frameworks, not raw logs. Additionally, automation should handle the repetitive work, including moving data between storage tiers, triggering deletion workflows when retention periods expire, and initiating access reviews on schedule.
The key stages of the data lifecycle
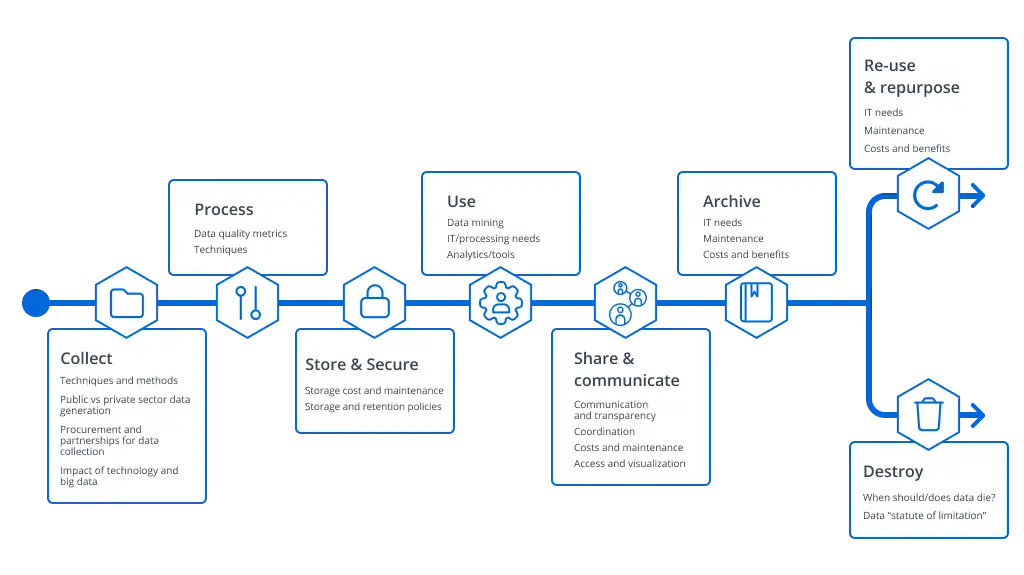
Every piece of data moves through predictable stages. Understanding these stages, and mapping governance tasks to each one, separates ad hoc data management from a defensible program.
Stage 1: Creation and collection
Governance starts at the point of ingestion, not months later when someone finally gets around to it. The moment data enters the environment, it should be classified by sensitivity (public, internal, confidential, regulated) and assigned to a business owner who is accountable for its lifecycle.
Metadata captured at this stage, including source, timestamp, lineage, and retention schedule, drives every downstream decision about how the data is stored, who can access it, and when it should be deleted.
Standard privacy and security frameworks reinforce this principle by requiring organizations to document the collection purpose and legal basis before data is gathered, not after it has already proliferated across systems.
Stage 2: Storage and maintenance
Where data lives should reflect how it is used and what it is worth. Active datasets supporting daily operations belong on high-performance storage with encryption at rest (AES-256), while less frequently accessed data should move to cheaper tiers.
Access controls need to align with the classification applied during Stage 1, using role-based access control (RBAC) that restricts sensitive data to the people and systems with a legitimate need.
Quarterly access reviews catch permission drift before it becomes a compliance finding, and backup configurations should align with the organization's RTO/RPO requirements so recovery expectations match reality.
Stage 3: Use and processing
This is where data creates business value, and where governance is easiest to neglect. As data moves through transformations, analytics pipelines, and business applications, quality needs to remain high. Degraded data leads to degraded decisions.
Monitoring usage patterns for anomalies helps surface unauthorized access or exfiltration attempts early, while masking or tokenizing sensitive data in non-production environments prevents exposure during testing and development.
The key principle here is enforcing purpose limitation through technical controls rather than relying on written policies that nobody checks.
Stage 4: Sharing, distribution, and archival
Once data crosses organizational boundaries, whether to partners, downstream systems, or long-term archival storage, the governance focus shifts to third-party risk. Vendor security assessments, data processing agreements, encryption in transit, and time-limited access with automatic expiration all reduce the probability that shared data ends up somewhere it should not.
Equally important is maintaining data lineage through external distribution. Without it, teams cannot respond to data subject requests or answer a fundamental question during an incident: where does this data actually live?
Stage 5: Retention and deletion
The stakes run in both directions. Delete too early, and the organization risks spoliation sanctions and regulatory penalties. Retain too long, and the accumulated data expands breach exposure, inflates storage costs, and can violate data minimization requirements under GDPR.
Getting this right requires aligning retention schedules with legal holds, regulatory rules, and internal policies. Before triggering any deletion workflow, teams should evaluate whether the data can be repurposed for another business function, since re-collection often costs more than continued retention.
Coordinating across legal, compliance, security, and IT is critical here; without it, policy drift and undocumented exceptions become the norm. Three operational areas demand particular attention:
- Legal hold management: Suspend automated deletion when litigation is anticipated, track all data under hold, and release holds promptly when lifted.
- Secure disposal: Implement certified sanitization following NIST SP 800-88 guidelines for physical media and cryptographic erasure for cloud-based data.
- Proof and completeness: Maintain deletion logs and certificates, and extend deletion to all copies, backups, and distributed instances.
Understanding these stages is one thing. Building the operational infrastructure to govern them is where most programs stall.
How to build a data lifecycle management strategy
Theory is useful, but implementation is what matters. The following five-step approach works for mid-market teams with real resource constraints.
Step 1: Inventory key systems and data domains
Start with a fundamental question: where does data actually live? Most organizations can name their primary databases and file shares, but the full picture includes:
- Sanctioned cloud repositories
- Shadow IT deployments nobody approved
- Data flows between systems that evolved organically
- Local copies that exist because someone needed a workaround three years ago
Mapping core data types across cloud, on-premises, and hybrid environments is the first step, but the inventory is incomplete without engaging business owners who understand how data is actually used, what regulatory obligations apply to it, and which repositories governance has never touched.
Step 2: Define lifecycle stages and policies for each domain
Standardize lifecycle stages across the organization, but allow domain-specific nuances:
- Customer PII has different retention requirements than server log data
- Financial records often follow multi-year retention timelines under SOX
- Healthcare compliance documentation commonly requires six-year retention under HIPAA
For each domain, define retention durations, access requirements, security controls, archival triggers, and legal hold processes aligned with applicable regulations.
Step 3: Map controls and tools to each stage
Policies without enforcement mechanisms are documentation, not governance. Each lifecycle stage needs to connect to the technical controls that make policies operational: backup systems, archiving platforms, encryption tools, access governance solutions, and monitoring infrastructure.
Identity-aware tools play a particularly important role here because they understand both the data and who can reach it.
When someone changes roles or a contractor's project ends, access rights need to adjust accordingly, and that adjustment should be driven by the lifecycle stage the data occupies, not a manual ticket someone remembers to file.
Step 4: Implement governance workflows and ownership
Assign data owners who are responsible for approving retention, access, and sharing decisions. These are typically business leaders with accountability for specific domains, not IT staff.
Establish workflows covering access requests, classification reviews, retention reviews, incident response, and data subject rights fulfillment. For most mid-market organizations, a hybrid model (centralized policy-setting with distributed execution) balances consistency with practical resource constraints.
Step 5: Measure, improve, and adapt
Track metrics across four categories:
- Compliance metrics: Percentage of data compliant with retention policies, time to respond to regulatory audits or DSARs, policy violations detected and remediated
- Operational metrics: Storage cost per data class versus baseline, percentage of data assets with defined owners, coverage of lifecycle policies across systems
- Quality metrics: Data accuracy rate, completeness of required fields, and freshness against SLAs
- Maturity metrics: Policy adoption rate across systems, governance training participation, percentage of critical data with documented lineage
Review lifecycle policies regularly in light of regulatory changes, new business initiatives, and emerging risks. Governance is an ongoing practice, not a project with a finish date.
Data lifecycle management starts with visibility
The throughline of data lifecycle management is accountability. At every stage, someone needs to know what data exists, who can reach it, whether it should still be there, and what happens if any of those answers are wrong. The organizations that treat DLM as an ongoing discipline rather than a one-time project are the ones that pass audits without scrambling, contain breaches faster, and avoid paying for storage nobody needs.
The hard part is not understanding what needs to happen. It is building the visibility to actually do it across hybrid environments where data, identities, and access rights are constantly shifting.
Netwrix 1Secure is built for exactly this problem. The platform connects sensitive data discovery and classification with identity-aware access governance and activity monitoring across on-premises and cloud environments.
This gives mid-market teams the continuous visibility that data lifecycle management demands, without enterprise-scale complexity.
Request a demo to see how Netwrix 1Secure delivers lifecycle visibility across hybrid environments
Frequently asked questions about data lifecycle management
Share on
Learn More
About the author

Farrah Gamboa
Sr. Director of Product Management
Senior Director of Product Management at Netwrix. Farrah is responsible for building and delivering on the roadmap of Netwrix products and solutions related to Data Security and Audit & Compliance. Farrah has over 10 years of experience working with enterprise scale data security solutions, joining Netwrix from Stealthbits Technologies where she served as the Technical Product Manager and QC Manager. Farrah has a BS in Industrial Engineering from Rutgers University.
Learn more on this subject
OpenAI and the environment AI inherits
NIST CSF 2.0: What's new in the Cybersecurity Framework
SOX compliance software: automating controls and audit evidence
Tokenization vs. encryption: Choosing the right data protection approach
Privileged Access Management solutions market: 2026 guide